

Blog
Apr 17, 2025
How to Transform Raw Data into Actionable Insights using Efficient Data Processing Pipelines


The ability to rapidly transform raw information into actionable insights is paramount for any data team. It’s becoming more important now, when the world will generate 181 zettabytes of data a year, up almost 3X from 64.2 zettabytes generated in 2020.
Whether it's building ML models, executing ETL/ELT workflows, performing complex calculations, or ingesting massive amounts of data, agility and speed are key to driving informed decisions. However, the volume and variety of data can make this process increasingly painful.
Here are 7 key factors that help make your workflows more efficient:
1. From Functions to Pipelines: A Practical Approach
Building efficient data pipelines can be achieved through an approach centered on plain Python functions, which avoids vendor lock-in and allows for easy understanding and extension of existing codebases. Existing code in your IDE should be seamlessly integrated into pipeline nodes with minimal effort, enabling teams to avoid making changes to their code, instead reuse valuable assets and significantly accelerate development and testing.
Key points:
Plain Python Functions (No Framework Lock-In)
Regular Function Composition for Dependencies
Seamless Integration of Existing Code
2. Containerized Execution
Docker provides a robust solution for consistent execution environments by running each pipeline node in its own isolated container, ensuring consistent environment variables, libraries, and dependencies across runs and preventing conflicts on shared infrastructure. Docker facilitates integration with CI/CD systems, simplifying collaboration and making debugging more manageable through the ability to inspect individual container states.
Key points
Isolated Docker Containers for Each Node
Identical Execution Environments Across Runs
Ideal for CI/CD, Debugging, and Collaboration
3. Automatic Data Passing Between Nodes
Traditional data pipelines often involve significant manual effort in connecting different components to ensure data flows correctly. Modern pipelines should be prepared to tackle this problem. Data inputs and outputs are automatically managed through the Directed Acyclic Graph (DAG), streamlining the entire process.
Examples of How This Works Transparently
Consider a scenario where data needs to flow from a data cleaning function to a feature engineering function, and then to a model training function.
Each function simply returns its processed data, and the pipeline framework handles the seamless transfer of this data to the next dependent step.
You don't need to explicitly define how the data is passed; it happens automatically.
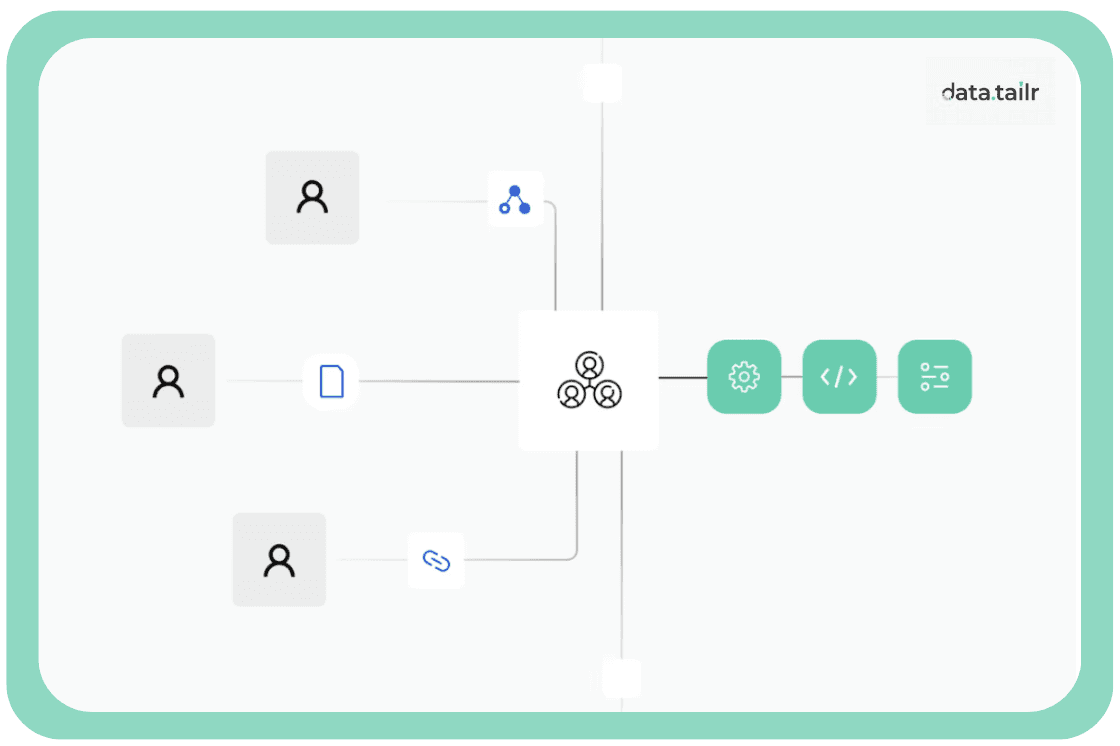
Data Processing Workflows | source : www.datatailr.com
4. Dependencies as Code, Not Configuration
Dependencies are defined directly in the code through function return values serving as inputs for subsequent functions, inherently defining the DAG structure. This eliminates the need for separate configuration files, leading to a cleaner and more intuitive development experience.
Key points:
Function return values define the DAG
No need for separate configuration files
Cleaner, more intuitive development
5. Real-Time Monitoring
Robust monitoring tools, available through visual or CLI interfaces, provide immediate visibility into the status of data processing tasks with live updates on running, succeeded, and failed states. Furthermore, event hooks and detailed logs enable custom observability, allowing teams to set up specific alerts and notifications.
Key points:
Visual or CLI-based pipeline monitor
Live status updates
Event hooks or logs for custom observability
6. Access to Intermediate Results
A significant advantage is the ability to access the outputs of each processing step post-run, proving invaluable for debugging and iterative development. This direct access to intermediate results allows for more effective experimentation and exploration of your data processes. Optional tools or APIs can further enhance the ability to query and analyze these intermediaries.
Key points:
Every step's outputs are accessible post-run
Ideal for debugging, iteration, or branching logic
Optional tooling or API to query artifacts
7. Smart Caching and Partial Re-Runs
Smart caching optimizes pipeline execution by remembering successfully completed nodes. Subsequent runs then recompute only the necessary parts, significantly reducing processing time and resource consumption, particularly benefiting iterative development workflows.
Key points:
Pipeline remembers succeeded nodes
Only necessary parts are recomputed
Significant time savings in iterative workflows
Want to see how Datatailr brings these 7 key efficiency factors to life out-of-the-box?
Use Cases and Examples for Data Teams
Machine Learning Pipelines: Automating the end-to-end process of data preparation, feature engineering, model training, evaluation, and deployment for various machine learning tasks.
ETL / ELT Workflows: Building robust and scalable pipelines for extracting, transforming, and loading (or extracting, loading, and transforming) data into data warehouses or data lakes for business intelligence and reporting.
Position & Risk Calculations: Developing pipelines to ingest market data, calculate portfolio positions, and perform complex risk analyses in a timely and reproducible manner.
Market Data Ingestion Pipelines: Creating scalable systems to ingest, clean, and normalize large volumes of real-time and historical market data from various sources.
Data Quality Pipelines: Implementing pipelines to continuously monitor and validate data quality, ensuring the reliability and accuracy of downstream analytics.
Closing Thoughts
Teams that implement these principles have accelerated their time-to-market for data-driven initiatives by 2X or more, while simultaneously realizing significant reductions in operational & cloud costs. By simplifying your workflows, ensuring reliability and observability, you can transform your data operations from a bottleneck into a powerful engine for innovation.
Ready to unlock this level of efficiency for your data team?
If you have any questions or you'd like to schedule a call, use this link: https://datatailr.com/contact-us


1177 Avenue of The Americas, 5th FloorNew York, NY 10036